Why Choose K3 Low-Code ETL for Data Orchestration AWS Redshift
Sophisticated data orchestration and storage require sophisticated solutions. Amazon Redshift has you covered for storage. Its massively parallel processing (MMP) database has set the standard for cloud-based data warehousing. As primarily a data warehouse, however, Redshift is geared to specific, fairly rigid workloads when it comes to data-driven decision-making. For truly robust data flow orchestration, processing, transaction computing, and analysis, however, you need a comprehensive extract, transform, load (ETL) platform.
As primarily a data warehouse, Amazon Redshift is geared to specific workloads. For truly robust data flow orchestration, processing, transaction computing, and analysis, combining Redshift’s storage power with K3 ETL delivers.
K3/Redshift Symbiosis
Pairing the premier cloud-structured data warehouse with the industry’s leading low-code ETL engine optimizes and scales enterprise data orchestration. It does this by separating computation and data science from the querying and data inventory functions. With K3 streaming, you achieve an air-tight relationship with Redshift through each step of the process. Here’s how:
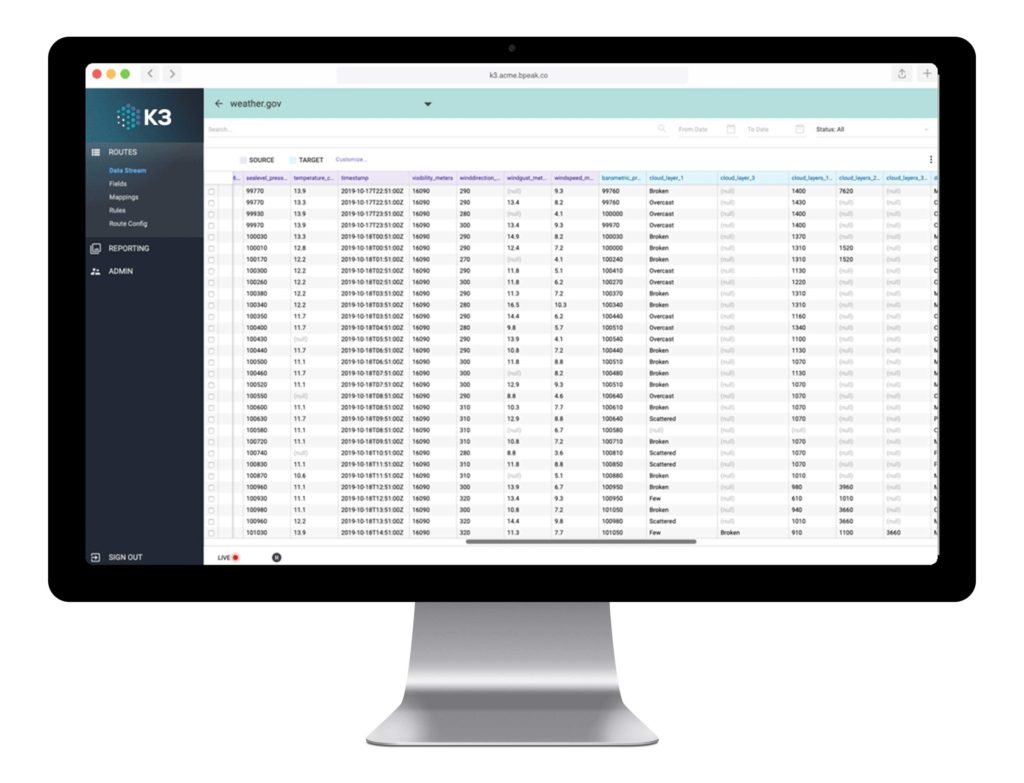
- Extraction – K3 for Amazon Redshift leverages AWS-optimized database migration component (or native AWS integrations for incompatible source data) to conduct change data capture tasks. This streamlines the pulling of data from other cloud-based and on-premises sources, files, and data lakes. Prebuilt K3 connectors integrate with hundreds of sources so data extraction is fully automated and synchronized with the downstream workflow.
- Transformation – Combine, calculate, and extrapolate insights from data efficiently and accurately with boilerplate and customized transformations scripts created in K3’s proprietary, low-code universe. All scripts and data transformation tasks can be scaled to read from and run on Amazon components.
- Loading – K3 conforms to Redshift’s features that allow data to be modeled for analysis purposes post-load. To enable this, K3 data load meticulously alters the data schema to allow marketing, finance, operations, and other business intelligence systems to view and use the data post-load through digital acrylic graphs (DAGs).
PRO TIP:
Separate computation and data science from the querying and data inventory functions to create synergy between Redshift and your streaming ETL platform.
How Data Orchestration Gets Done
K3’s data pipeline orchestration tools connect and simplify several steps, including:
- K3 Data Prep – Incoming data rarely acts on its own. Instead, data prep includes altering data point taxonomies to help the newcomers assimilate with the established residents.
- Timing – Data becomes available at different times and some queries take longer than others to execute. K3 coordinates the arrival and distribution of data to maintain synchronicity.
- Governance – K3 ETL includes filters and decision engines that decide – based on your business rules – which data will be accepted, which will be rejected out of hand, and which will be quarantined pending further analysis.
Offloading the ETL function to K3 enables Redshift to focus on what it does best. K3 does the heavy lifting involved by coordinating the activities and tasks required to evaluate the data, filter it to the business intelligence processors, display the results, and guide actionable insights.
Let us show you how we do it.