Data is king for small, medium and large organizations alike, but data can also be a monster lurking under the bed. Terms like data lake, ETL (extract, transform, load) and data warehousing sometimes intimidate even the savviest business professionals. No matter how daunting, however, modern data collection isn’t slowing down. By 2025, it is estimated that the amount of data generated each day[CT1] will reach 463 exabytes[CT2] globally. But don’t worry; there are ways to seamlessly prep data from a wide variety of sources and feed it into your hungry data repository.
Data collection isn’t slowing down. By 2025, 463 exabytes will be generated each day around the globe. Learn how the #ETL process makes it possible to harness the power of filtered, meaningful data.
If your business is using Snowflake or Amazon Redshift, it’s in good company. Snowflake was named 2020’s fastest growing SaaS company, while Redshift users include organizational giants such as McDonald’s, Philips and Pfizer. With data management growing at rapid speed, there are some important considerations when preparing data using ETL for Snowflake and Redshift.
Don’t let data be a monster lurking under the bed. Make sure ETL is performed correctly so your organization can make more informed business decisions, analyze performance scalability and even mitigate risk
1. ETL is complex.
ETL refers to the extraction of data, the transformation of data and the loading of data. The method itself is not merely three well-defined steps, but a broader process that is multifaceted. To explain it simply, during extraction, data is collected from a variety of different sources such as databases and applications. Next, all that raw data needs to be transformed since much of it looks different. For example, customer might be referred to as both “cust” and “customer” so the information needs to be streamlined in order to create quality data. To accomplish this, rules or functions are used to prepare the extracted data for its end target. Last, but not least, the data is loaded into a destination such as a database or data warehouse
PRO TIP:
ETL is a complicated progression of steps, but it can be made easier with powerful, pre-built integrations for a wide variety of destinations.2. ETL tools offer much-needed muscle.
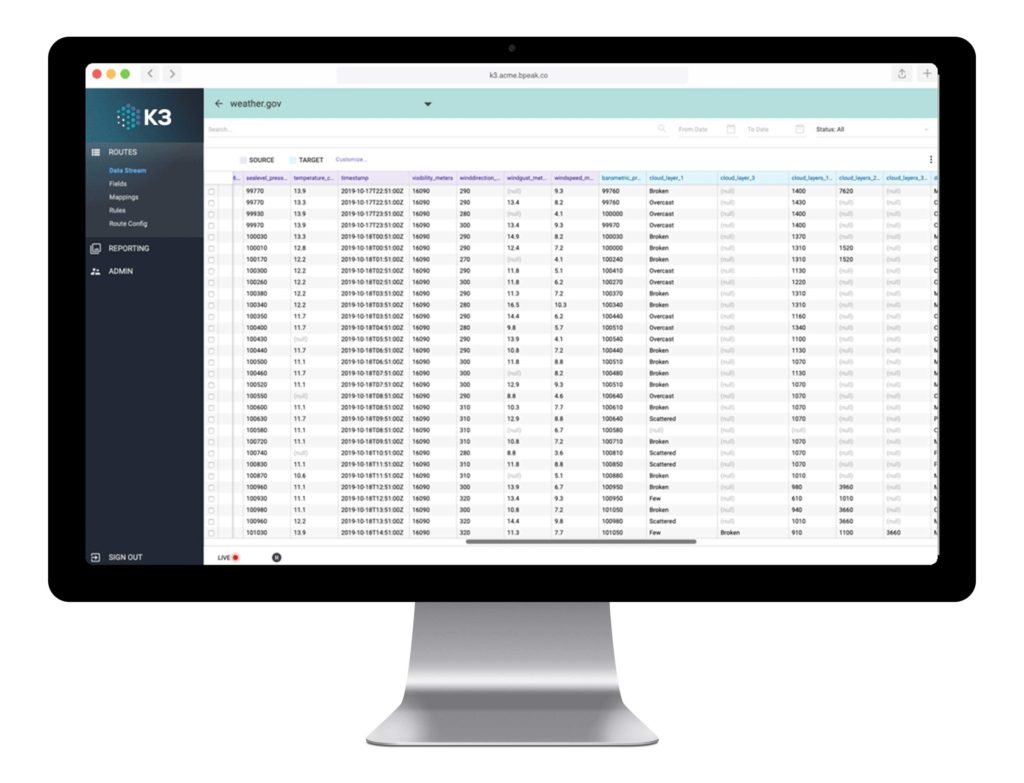
ETL is key to transforming raw data into useable information. ETL tools, like our K3 ETL, are designed to get data moving downstream. K3 for Snowflake has off-the-shelf connectivity that delivers better control, the ability to clean and store data, and a customizable framework designed to capture lost data. K3 for Redshift moves data seamlessly using intuitive visual data mapping without an on-premise infrastructure or pricey database.
PRO TIP:
Using an ETL tool helps your organization make more informed business decisions, analyze performance scalability and even mitigate risk.3. K3 ETL tools simplify the process.
PRO TIP:
Use K3 ETL for its easy-to-use interface, simple to complex mapping with an intuitive UI and the ability to build personalized data rules right in the user interface.