“Just give me the raw data, Bob.” That could be the catchphrase of the year. The days of cube reporting, locked down databases and IT generally holding data hostage are over. In its place, non-coders are taking MS Power BI, Tableau, Spotfire (pick your poison) to new levels. Just give us the raw data and let us do our jobs!
But, like anything else. Garbage in is garbage out … The data struggle is never over. Here is the rub. Unless you have a penchant for vlookups and want that to be…say literally 80% of your day some tooling is in order. Most users will need software to “wrangle” data. Call it what you like: Data wrangling, Data prep, data cleanup, data harmonization we are taking data from multiple sources and making the data ready for Do It Yourself Business Intelligence.
This is the most time consuming part of the process.
So what does that data user need? A tool for getting the data from these various sources and “wrangling” it into a single rectangle, a database table with common enumerations and formats of values.
They also need the ability to iterate through changes because as soon as you start analyzing data in a picture, you often find the need for a new data element or a change to the logic you used to combine the various sources into the one powering your visualization.
This is actually where people trying to squeeze the information lemonade from the data lemons spend most of their time. Let’s get into it.
Data Mapping Basics
Data Wrangling has been around for at least a dozen years or so as a concept. Why “wrangling?” Well, because it’s historically dirty and takes grit and perseverance. It’s getting the data, combining the data, and then making it available for further use downstream. Let’s dive into “combining,” which has the highest degree of entropy amongst those elements.
Combining disparate sources starts with “Data Mapping” which is somewhat table-stakes in the ETL (extract transform load) process.
In most applications you will see something like this. You might recognize this mapping from your own legacy ETL application.
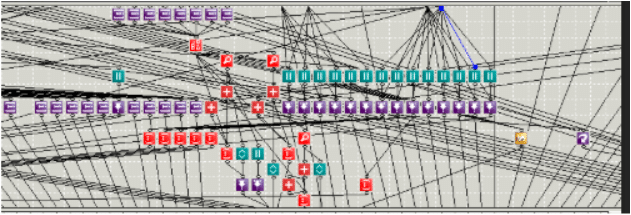
Actually…just kidding. I turned this one sideways to point out how absolutely useless and meaningless these types of line drawn mappings are at enterprise scale. I mean, how do you even go about debugging that?
Here is the Basic Problem
What is mapping for? Basically it is transiting field values from one to another. Call it what you like: data crosswalk, master data, mapping whatever…It all boils down to this: you have a set of source data elements. We need to change these up to what our target calls those same things. Here’s an example.
| Source System | Target System |
| Addr | Address |
| CS | Customer |
| Cost | Price |
| Number | Quantity |
Here’s a neat fact. When two systems talk about the same thing the chance of them using the same terminology is about 1%. Just like above. The Source System uses the term Addr and the second system uses the term address. (Because of course they do).
In most applications they are going to ask you to draw some cute little lines between source and target. What this is saying is: “Hey, when data comes under the source field “Addr,” I want you to pass it through to the target field ”Address.” Likewise when data comes under the source field “Person,” I want to pass it through to target field “Customer.”
It’s a valuable first step. But only a first step. What also needs to happen is deep mapping and enrichment.
Deep mapping thinks not just about the header values, but the values that come in under that column. That is how you get data to look consistent so you can ask yourself questions that span data sources. Think about it like this:
| CS | Customer |
| JWrangler | James Wrangler |
| CCATS | Charlie Cats |
| Tom Bojangles | Tom Bojangles |
| Puppers99@yahoo.com | Wayne Letterkenny |
Simply uniting all the CS to Customer won’t let you slice revenue by “James Wrangler” if there are 3 different versions of James Wrangler in your data set. For example, “JWrangler,” “J_Wranglert,” “Wrangler, Jim.”
The ability to do this mapping cleanly and efficiently is just one little gem in the K3 Data Wrangling tool chest. As with everything else mapping is done on a streaming basis (Batch is so 1999). You put in CS | CCATS and you instantly get back Charlie Cats.
Next Up. Data Wrangling: Creating Data Rules
Follow Up to that: Mapping: Data Wrangling: Meta-Data